S3 Access Control is Nice to Set and Hard to Maintain
For a security practitioner, the challenge with S3 is to maintain the balance between enjoying the advantages of cloud storage and keeping the necessary caution.
Advantages:
The S3 service is fully managed by Amazon
Amazon takes responsibility for infrastructure, hardware, networking, operating system, application software and manages all respective security topics.High security standards
AWS as a cloud provider has the necessary economies of scale to maintain high security standards for the S3 service, which are very hard to match for any IT team, even from very large companies.
Caution:
Every mistake counts
The fundamental properties of S3 as a cloud service has no layers of defense, which would otherwise be there in your traditional environment, e.g. no firewalls, no closed user groups.Access Control is your responsibility
The security of your data in S3 relies fully on the correct access control settings, which are in your responsibility and have to be maintained at all times.
Unfortunately, S3 access control is nice to set and hard to maintain:
The access permissions schema, via so-called “policies”, is very flexible and the developer can initially implement all what is demanded from him/her for a certain project. Knowledge of the rather technical JSON syntax is not a real hurdle for developers.
After some time, permissions have to be reviewed for correctness and this may require not only know-how down to the specific details of policies written in JSON syntax, but also the location of the relevant policy items, which may reside in various parts of the system.
Adding to the complexity is the legacy way to set access control with ACLs, which also would have to be evaluated if they existed in a given environment.
Let us discuss the issues one by one.
Fundamental Properties of S3 and their Surprising Effects
Amazon S3 (Simple Storage Service) is one of the earliest cloud services by Amazon, started by Amazon in 2006. Its flexibility for storing objects of all sizes from several kByte to several TByte has made S3 one of the most popular services of AWS. However, through its history S3 has acquired a number of features, which may be surprising for users new to AWS:
Global Service and the Owner’s Responsibility
An important characteristic of the S3 service, which it has in common with most other cloud services, is its universal connectivity: It can be reached from everywhere on the Internet, a possible exception being China. Data in S3 are organized as buckets to distinguish responsibilities. If you are the owner of a bucket on S3, you are the only one, who can and must define who gets access to the data in the bucket and who does not. There is no other instance, especially not AWS, who would take care of your responsibility. In fact, a single attribute in S3 designating the owner makes all the difference.
Global Namespace
The name of every bucket is defined in a worldwide context. This has the somewhat unfamiliar effect that you cannot choose a bucket name as you like, because the name may already have been taken by someone else. For example, the bucket “www.amazon.com" cannot be created by you. It is presumably owned by Amazon itself. As there more than 1 million accounts on AWS, you can imagine that all words from dictionaries and even their combinations have been taken already.

Once you delete a bucket, you may not be able to recreate it with the same name:
In fact, at the time of this writing (Oct 2016), if you delete a bucket and try to create it in a different region, you get the following error message in the console for about 1 hour:
Data Location
The S3 console is consistent with the global namespace and does not distinguish between regions. During the creation of a bucket the owner specifies the location of the data and Amazon guarantees that the data remain in the same region, thereby staying in the same legislature. There is a flipside to it: You cannot move a bucket to another location. You would have to delete it, and recreate it at another location. The latter may turn out not to be possible, if it had an attractive name which was taken by someone else in the meantime.
S3 Access Control is nice to Set and hard to Maintain
Because access to a bucket is neither restricted by connectivity or namespace, anyone can make a request to your buckets. This puts the burden of access control completely on configuring the right permissions, there is no defense-in-depth against misconfigurations.
Lets have a closer look how permissions are configured and reviewed:
Access Control with ACLs
S3 has two fundamentally different access control mechanisms: Access Control List (ACL) and bucket policy. While ACL is featured more prominently in the user interface, it is actually the older method and does not provide enough flexibility for many use cases.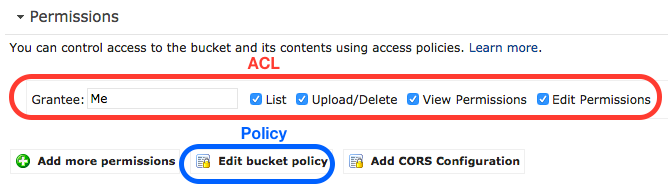
Access Control with Policies
Bucket policy has come after ACLs and with its JSON format is much more powerful than ACLs. The “AWS Policy Generator” helps in navigating the possibilities. However, when someone is changing or reviewing permissions, he/she must understand the JSON syntax and the semantics. A simple example is the following policy for granting read access to everyone from the AWS reference:
{
"Version":"2012-10-17",
"Statement":[
{
"Sid":"AddPerm",
"Effect":"Allow",
"Principal": "*",
"Action":["s3:GetObject"]
"Resource":["arn:aws:s3:::examplebucket/*"]
}
]
}As you can see from this simplest example, the understanding of access policies requires know-how both in JSON syntax and in AWS vocabulary. In practice the permissions are getting much more complex and anybody changing or reviewing them must fully understand the details or is taking risks.
Policies at Many Places
In summary, the following object types, ordered from generic to specific, can grant or deny access to your data in S3:
- IAM Policy
- AWS-managed policy attached to a user, group or role
- Self-managed policy attached to a user, group or role
- Inline policy for a user, group, or role
- Bucket Policy
- Bucket ACL
- Object ACL
This gives a large degree of flexibility for implementing access control. There is no advice from AWS, whether using IAM policies or bucket policies would generally be better. Instead, for every use case the choice may be different depending on specific requirements. There are even use cases, where Bucket ACL or even Object ACLs must be used, because policies are not covering all aspects.
The flipside is in maintenance, because someone reviewing access control would have to cover every possibility, where a relevant policy could have been stored (of course, besides checking the ACLs). To help with this task, AWS provides the “IAM policy simulator”, which shows the access rule (allow, deny) for an access target and the policy which granted the access.
Policy Simulator and the Finer Details
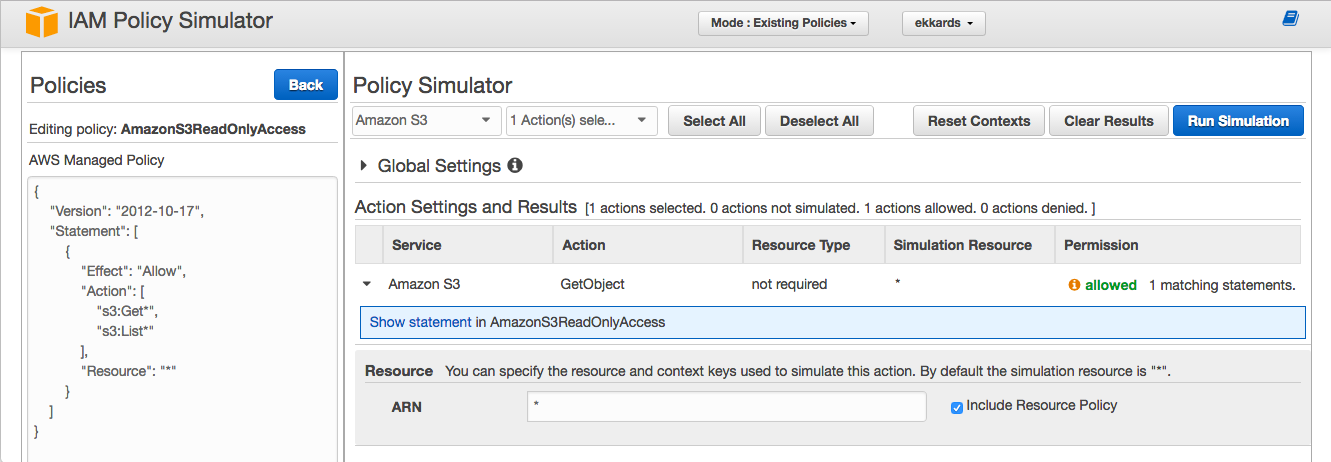
The practitioner can use the simulation as a hint, where to look for further details, but cannot fully rely on the answer, because it depends on the precise request chosen. The questions asked in the above screenshot above was: “Has a specific user read access to all buckets” and the answer is accurately “yes”, because the policy “AmazonS3ReadOnlyAccess” has been assigned to this user.
However, if the simulation shows “denied”, this can be misleading. For example, in the example below the question was asked whether a user “Dave” has access to a specific bucket and the answer was “denied”.
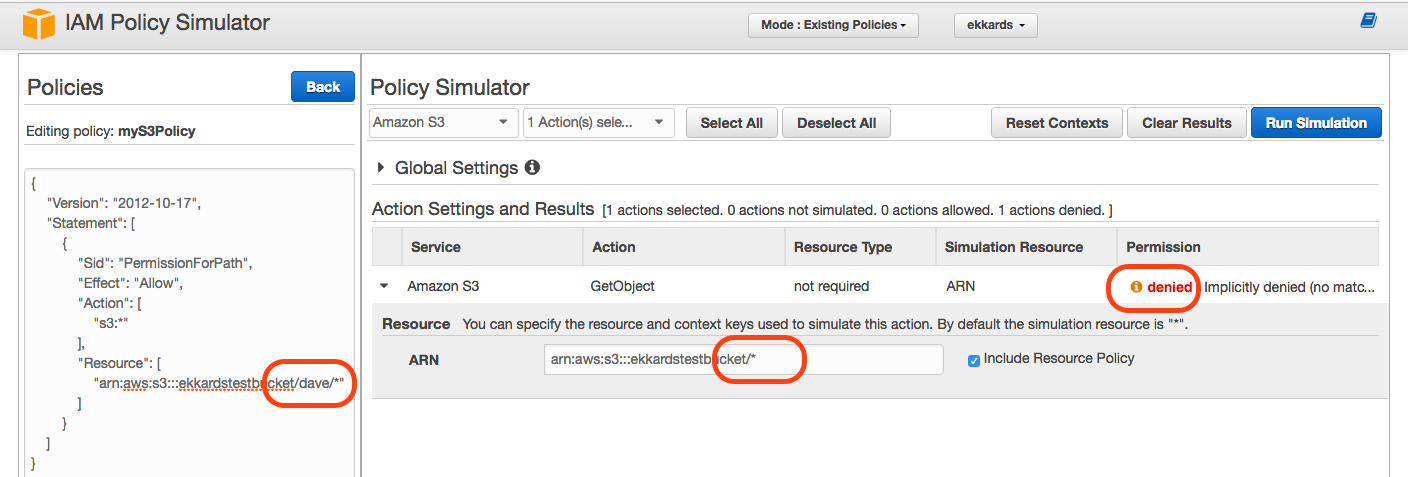
However, one can see from the policy JSON on the left that access is granted for a path ”/dave/*” inside the bucket. Running the simulation again with the correct question, whether Dave has access to the contents of the folder “/dave/*” yields the accurate result “allow”:
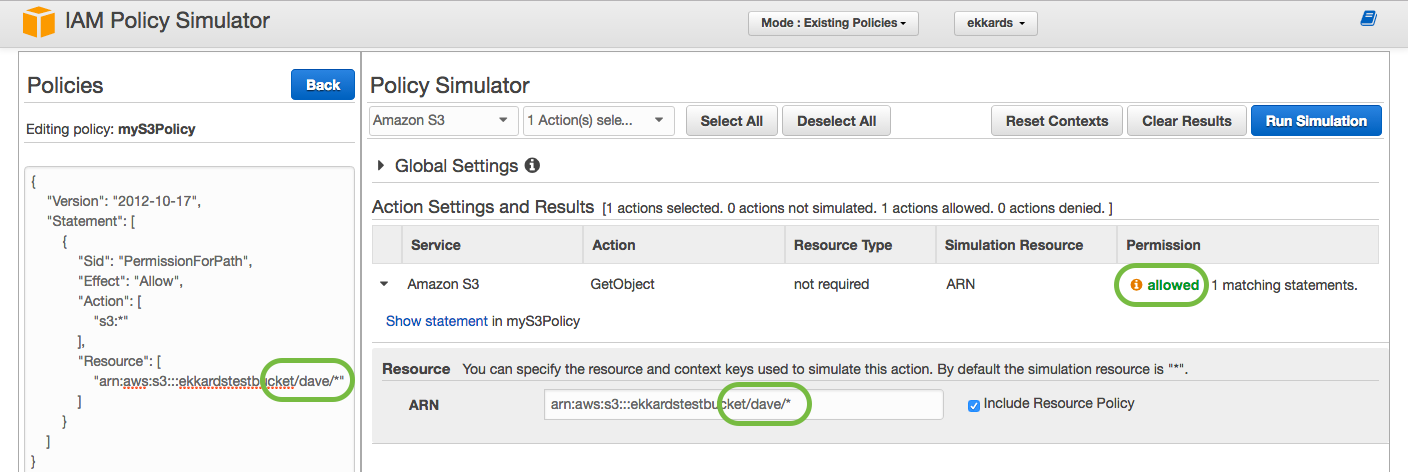
Recommendations
Configuration Checks
Check the data location of your buckets
If you created buckets programmatically and no LocationConstraint was specified during creation, the bucket will have been created in USA (region us-east-1). This is a source of error, which should be checked.Claim your bucket names in the global namespace
I would recommend that you create buckets for your registered DNS names.
There are connections between DNS names in Route 53 and bucket names in S3 for website hosting. Because Amazon does not enforce restrictions on brand names you may later run into troubles.
Access Checks
Avoid the use of ACLs for buckets
ACLs on bucket are only needed in singular cases like log collection.
For all other cases, rewrite the ACLs in terms of policies and remove the ACL except the default “Me” “Full Control”, to avoid surprises from unwanted access.Perform a regular access review on your buckets
The access review should list all relevant policies and which user has access to which bucket.
Hacking, Security Bulletins, Patching and Emergencies
This document is by no means an instruction how to hack S3. Quite to the contrary, we assume that that S3 works as described and we just play by the rules laid down by AWS. However, we know that not everyone plays by the rules and may try to break the S3 controls, which are maintained by AWS. Despite all certifications of AWS there is always the possibility that a vulnerability exists, and can be exploited. AWS informs about vulnerabilities via Security Bulletins from AWS, e.g. https://aws.amazon.com/security/security-bulletins/openssl-security-advisory-may-2016/. In many cases, AWS has the responsibility to fix the vulnerability by patching, especially for S3. In other cases, action on our part may be needed. In extreme cases it would be our duty to decide whether we would need to stop our services to avoid potential damages. Fortunately, as most of the S3 infrastructure is under control of AWS, this is more a theoretical possibility than a practical consideration.
Encryption
Encryption is often named as an important security measure for cloud computing. This is certainly true for data-in-transit, and all data transmissions to and from S3 are encrypted with SSL, if the common access paths are used (Console, AWS SDK, AWS CLI). The possible exceptions are public websites hosted on S3. This works so well that the cloud user does not even notice it.
Also data-at-rest can be encrypted on S3 by setting an attribute on the object itself, there is no setting for the bucket:
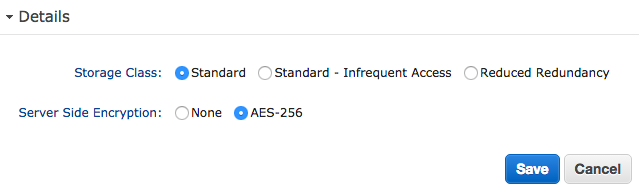
The encryption is performed by the S3 service completely transparent for the user. The data received from the user are encrypted before saving them to disk and are read from disk and decrypted before sending them to the user. Because the user will not notice any difference, encryption can and should be enabled for every object.
However, server side encryption can only protect against internal threats inside AWS, e.g. if a hacker would have access to the file system underlying the S3 service, or a hard disk would be lost. It would not strengthen access control, because all users with access, legitimate or not, receive the decrypted data. If more protection for the data would be needed, key management would become an issue.
Key Management
Encryption works so easily, because key management is handled by AWS, who have to keep the keys secure. If a key would be lost, the corresponding data would be lost. A reliable and secure key management is a mandatory prerequisite for encrypting data-at-rest.
This document will not cover higher protection requirements, which some companies may have for some of their data. In this case the cloud user organization would have to perform their own key management and/or encryption and decryption. To make this easier, AWS offers the KMS (Key Management Service) and associated encryption libraries with their SDKs.
Implementing key management and/or encryption could mean considerable effort, and would void the advantage of S3 as a universal interface for storage. Data are rarely stored and retrieved by a single application, but usually serve many applications, which all must have access to the keys and implement the decryption algorithm. In consequence, for most use cases an own key management and encryption is too inflexible and economically unfeasible.
Conclusion
In conclusion, S3 security may look deceptively simple, but the effort in keeping it secure can be high, if done properly. We automate your security chores for Amazon S3.
By Ekkard Schnedermann, October 2016